
NVIDIA NeMo Framework

Տեխնիկական պայմաններ
- Ապրանքի անվանումըNVIDIA NeMo Framework
- Ազդեցության ենթարկված հարթակներ. Windows, Linux, macOS
- Ազդված տարբերակները՝ Բոլոր տարբերակները մինչև 24
- Անվտանգության խոցելիություն. CVE-2025-23360
- Ռիսկի գնահատման բազային միավոր՝ 7.1 (CVSS v3.1)
Ապրանքի օգտագործման հրահանգներ
Անվտանգության թարմացման տեղադրում.
Ձեր համակարգը պաշտպանելու համար հետևեք հետևյալ քայլերին.
- Ներբեռնեք վերջին թողարկումը GitHub-ի NeMo-Framework-Launcher Releases էջից։
- Լրացուցիչ տեղեկությունների համար այցելեք NVIDIA արտադրանքի անվտանգության բաժինը։
Անվտանգության թարմացման մանրամասները՝
Անվտանգության թարմացումը լուծում է NVIDIA NeMo Framework-ի խոցելիությունը, որը կարող է հանգեցնել կոդի կատարմանը և տվյալների կորստի։ampering.
Softwareրագրաշարի արդիականացում.
Եթե օգտագործում եք ավելի վաղ տարբերակ, խորհուրդ է տրվում թարմացնել այն վերջին տարբերակով՝ անվտանգության խնդիրը լուծելու համար։
Ավարտվել էview
NVIDIA NeMo Framework-ը մասշտաբային և ամպային գեներատիվ արհեստական բանականության շրջանակ է, որը մշակվել է հետազոտողների և մշակողների համար, որոնք աշխատում են... Լեզուների մեծ մոդելներ, Մուլտիմոդալ և Խոսքի արհեստական բանականություն (օրինակ Ավտոմատ խոսքի ճանաչում և Տեքստ-խոսք)։ Այն թույլ է տալիս օգտատերերին արդյունավետորեն ստեղծել, հարմարեցնել և տեղակայել նոր գեներատիվ արհեստական բանականության մոդելներ՝ օգտագործելով առկա կոդը և նախապես պատրաստված մոդելի ստուգիչ կետերը։
Կարգավորման հրահանգներ: Տեղադրեք NeMo Framework-ը
NeMo Framework-ը ապահովում է ամբողջական աջակցություն մեծ լեզվական մոդելների (LLM) և բազմամոդալ մոդելների (MM) մշակման համար: Այն ապահովում է ճկունություն՝ տեղում, տվյալների կենտրոնում կամ ձեր նախընտրած ամպային մատակարարի հետ օգտագործելու համար: Այն նաև աջակցում է SLURM կամ Kubernetes-ի աջակցությամբ միջավայրերում կատարողականին:

Տվյալների հավաքագրում
NeMo-ի կուրատոր [1] Python գրադարան է, որը ներառում է տվյալների արդյունահանման և սինթետիկ տվյալների ստեղծման համար նախատեսված մոդուլների մի շարք: Դրանք մասշտաբային են և օպտիմիզացված GPU-ների համար, ինչը դրանք իդեալական է դարձնում բնական լեզվի տվյալների մշակման համար՝ LLM-ների ուսուցման կամ ճշգրտման համար: NeMo Curator-ի միջոցով դուք կարող եք արդյունավետորեն արդյունահանել բարձրորակ տեքստ ծավալուն հումքից: web տվյալների աղբյուրներ։
Ուսուցում և անհատականացում
NeMo Framework-ը տրամադրում է գործիքներ արդյունավետ ուսուցման և հարմարեցման համար։ LLMs և բազմամոդալ մոդելներ: Այն ներառում է հաշվողական կլաստերի կարգավորման, տվյալների ներբեռնման և մոդելի հիպերպարամետրերի լռելյայն կարգավորումներ, որոնք կարող են ճշգրտվել նոր տվյալների հավաքածուների և մոդելների վրա մարզվելու համար: Նախնական մարզումից բացի, NeMo-ն աջակցում է ինչպես վերահսկվող նուրբ կարգավորման (SFT), այնպես էլ պարամետրերի արդյունավետ նուրբ կարգավորման (PEFT) տեխնիկաներին, ինչպիսիք են LoRA-ն, Ptuning-ը և այլն:
NeMo-ում մարզումները մեկնարկելու համար հասանելի են երկու տարբերակ՝ օգտագործելով NeMo 2.0 API ինտերֆեյսը կամ NeMo Run-ը։
- NeMo Run-ի հետ (առաջարկվում է). NeMo Run-ը տրամադրում է ինտերֆեյս՝ տարբեր հաշվողական միջավայրերում փորձերի կարգավորումը, կատարումը և կառավարումը հեշտացնելու համար: Սա ներառում է աշխատանքների մեկնարկը ձեր աշխատանքային կայանում տեղական կամ մեծ կլաստերներում՝ թե՛ SLURM-ով աշխատող, թե՛ Kubernetes-ով՝ ամպային միջավայրում:
- Նախնական մարզում և PEFT արագ մեկնարկ NeMo Run-ի միջոցով
- NeMo 2.0 API-ի օգտագործումը՝ Այս մեթոդը լավ է աշխատում փոքր մոդելներ ներառող պարզ կարգավորման հետ, կամ եթե դուք հետաքրքրված եք ձեր սեփական տվյալների բեռնիչը, մարզման ցիկլերը կամ մոդելի շերտերը փոխելով։ Այն ձեզ ավելի մեծ ճկունություն և վերահսկողություն է տալիս կարգավորումների նկատմամբ, ինչպես նաև հեշտացնում է կարգավորումների ծրագրային ընդլայնումն ու հարմարեցումը։
-
ԹրաԱրագ մեկնարկի ներդրում NeMo 2.0 API-ով
-
NeMo 1.0-ից NeMo 2.0 API-ի անցում
-
Հավասարեցում
- NeMo-Aligner [1] մասշտաբային գործիքակազմ է մոդելների արդյունավետ համաձայնեցման համար: Գործիքակազմն աջակցում է ժամանակակից մոդելների համաձայնեցման ալգորիթմների, ինչպիսիք են SteerLM-ը, DPO-ն, մարդկային հետադարձ կապի միջոցով ուժեղացված ուսուցումը (RLHF) և շատ ավելին: Այս ալգորիթմները թույլ են տալիս օգտատերերին համաձայնեցնել լեզվական մոդելները՝ դրանք ավելի անվտանգ, անվնաս և օգտակար դարձնելու համար:
- NeMo-Aligner-ի բոլոր ստուգիչ կետերը խաչաձև համատեղելի են NeMo էկոհամակարգի հետ, ինչը թույլ է տալիս հետագա հարմարեցում և եզրակացությունների տեղակայում։
RLHF-ի բոլոր երեք փուլերի քայլ առ քայլ աշխատանքային հոսքը փոքր GPT-2B մոդելի վրա.
- SFT ուսուցում
- Պարգևատրման մոդելի վերապատրաստում
- PPO-ի վերապատրաստում
Բացի այդ, մենք ցուցադրում ենք աջակցություն տարբեր այլ նորարարական հավասարեցման մեթոդների համար՝
- DPOթեթև հավասարեցման ալգորիթմ՝ համեմատած RLHF-ի հետ՝ ավելի պարզ կորստի ֆունկցիայով։
- Ինքնախաղ Նուրբ կարգավորում (SPIN)
- SteerLM: պայմանական SFT-ի վրա հիմնված տեխնիկա՝ կառավարելի ելքով։
Ավելի շատ տեղեկությունների համար ծանոթացեք փաստաթղթերին. Հավասարեցման փաստաթղթեր
Մուլտիմոդալ մոդելներ
- NeMo Framework-ը տրամադրում է օպտիմիզացված ծրագրային ապահովում՝ մի քանի կատեգորիաներում ժամանակակից մուլտիմոդալ մոդելներ մարզելու և տեղակայելու համար՝ մուլտիմոդալ լեզվական մոդելներ, տեսողական լեզվի հիմունքներ, տեքստից պատկեր մոդելներ և այլն՝ նեյրոնային ճառագայթման դաշտերի (NeRF) միջոցով 2D ստեղծում։
- Յուրաքանչյուր կատեգորիա նախագծված է ոլորտի կոնկրետ կարիքներին և առաջընթացներին համապատասխանելու համար՝ օգտագործելով առաջատար մոդելներ՝ տվյալների լայն տեսականի, այդ թվում՝ տեքստ, պատկերներ և եռաչափ մոդելներ մշակելու համար։
Նշում
Մենք բազմամոդալ մոդելների աջակցությունը տեղափոխում ենք NeMo 1.0-ից NeMo 2.0: Եթե ցանկանում եք ուսումնասիրել այս ոլորտը մինչ այդ, խնդրում ենք դիմել NeMo 24.07 (նախորդ) թողարկման փաստաթղթերին:
Տեղակայում և եզրակացություն
NeMo Framework-ը տրամադրում է LLM եզրակացության տարբեր ուղիներ՝ հաշվի առնելով տարբեր տեղակայման սցենարներ և կատարողականի կարիքներ։
Տեղակայել NVIDIA NIM-ի միջոցով
- NeMo Framework-ը անխափան ինտեգրվում է ձեռնարկությունների մակարդակի մոդելի տեղակայման գործիքների հետ NVIDIA NIM-ի միջոցով: Այս ինտեգրացիան ապահովվում է NVIDIA TensorRT-LLM-ի կողմից՝ ապահովելով օպտիմալացված և մասշտաբային եզրակացություն:
- NIM-ի մասին լրացուցիչ տեղեկությունների համար այցելեք NVIDIA կայքը։ webկայք։
Տեղակայել TensorRT-LLM-ով կամ vLLM-ով
- NeMo Framework-ը առաջարկում է սկրիպտներ և API-ներ՝ մոդելները երկու եզրակացության համար օպտիմիզացված գրադարաններ՝ TensorRT-LLM և vLLM, արտահանելու և արտահանված մոդելը NVIDIA Triton Inference Server-ում տեղակայելու համար։
- Օպտիմալացված կատարողականություն պահանջող սցենարների համար NeMo մոդելները կարող են օգտագործել TensorRT-LLM-ը, որը մասնագիտացված գրադարան է NVIDIA GPU-ների վրա LLM եզրակացությունը արագացնելու և օպտիմալացնելու համար: Այս գործընթացը ներառում է NeMo մոդելների փոխակերպումը TensorRT-LLM-ի հետ համատեղելի ձևաչափի՝ օգտագործելով nemo.export մոդուլը:
- LLM տեղակայումը ավարտվեցview
- Տեղակայեք NeMo Large Language Models-ը NIM-ի միջոցով
- NeMo Large Language Models-ի տեղակայում TensorRT-LLM-ի միջոցով
- Տեղակայեք NeMo Large Language Models-ը vLLM-ի միջոցով
Աջակցվող մոդելներ
Լեզուների մեծ մոդելներ
| Լեզուների մեծ մոդելներ | Նախնական մարզում և SFT | ՊԵՖՏ | Հավասարեցում | 8-րդ շրջանակի ուսումնական կոնվերգենցիա | TRT/TRTLLM | Փոխակերպել դեպի և դեպի գրկախառնվող դեմք | Գնահատում |
|---|---|---|---|---|---|---|---|
| Լամա3 8Բ/70Բ, Լամա3.1 405Բ | Այո՛ | Այո՛ | x | Այո (մասամբ ստուգված է) | Այո՛ | Երկուսն էլ | Այո՛ |
| Միքստրալ 8x7B/8x22B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | Այո՛ | Երկուսն էլ | Այո՛ |
| Նեմոտրոն 3 8Բ | Այո՛ | x | x | Այո (չհաստատված) | x | Երկուսն էլ | Այո՛ |
| Նեմոտրոն 4 340Բ | Այո՛ | x | x | Այո (չհաստատված) | x | Երկուսն էլ | Այո՛ |
| Բայչուան2 7Բ | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Երկուսն էլ | Այո՛ |
| ՉաթGLM3 6Բ | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Երկուսն էլ | Այո՛ |
| Գեմմա 2B/7B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | Այո՛ | Երկուսն էլ | Այո՛ |
| Գեմմա2 2B/9B/27B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Երկուսն էլ | Այո՛ |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | x | Այո՛ |
| Phi3 մինի 4k | x | Այո՛ | x | Այո (չհաստատված) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | Այո՛ | Երկուսն էլ | Այո՛ |
| ՍթարԿոդեր 15Բ | Այո՛ | Այո՛ | x | Այո (չհաստատված) | Այո՛ | Երկուսն էլ | Այո՛ |
| StarCoder2 3B/7B/15B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | Այո՛ | Երկուսն էլ | Այո՛ |
| ԲԵՐՏ 110Մ/340Մ | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Երկուսն էլ | x |
| T5 220M/3B/11B | Այո՛ | Այո՛ | x | x | x | x | x |
Տեսողական լեզվի մոդելներ
| Տեսողական լեզվի մոդելներ | Նախնական մարզում և SFT | ՊԵՖՏ | Հավասարեցում | 8-րդ շրջանակի ուսումնական կոնվերգենցիա | TRT/TRTLLM | Փոխակերպել դեպի և դեպի գրկախառնվող դեմք | Գնահատում |
|---|---|---|---|---|---|---|---|
| ՆեՎԱ (LLaVA 1.5) | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Սկսած | x |
| Լամա 3.2 Vision 11B/90B | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Սկսած | x |
| LLaVA Next (LLaVA 1.6) | Այո՛ | Այո՛ | x | Այո (չհաստատված) | x | Սկսած | x |
Ներկառուցված մոդելներ
| Ներդրման լեզվի մոդելներ | Նախնական մարզում և SFT | ՊԵՖՏ | Հավասարեցում | 8-րդ շրջանակի ուսումնական կոնվերգենցիա | TRT/TRTLLM | Փոխակերպել դեպի և դեպի գրկախառնվող դեմք | Գնահատում |
|---|---|---|---|---|---|---|---|
| ՍԲԵՐՏ 340Մ | Այո՛ | x | x | Այո (չհաստատված) | x | Երկուսն էլ | x |
| Լլամա 3.2 Ներդրում 1Բ | Այո՛ | x | x | Այո (չհաստատված) | x | Երկուսն էլ | x |
Համաշխարհային հիմնադրամի մոդելներ
| Համաշխարհային հիմնադրամի մոդելներ | Հետթրեյնինգ | Արագացված եզրակացություն |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | Այո՛ | Այո՛ |
| Cosmos-1.0-Diffusion-Text2World-14B | Այո՛ | Այո՛ |
| Cosmos-1.0-Diffusion-Video2World-7B | Շուտով | Շուտով |
| Cosmos-1.0-Diffusion-Video2World-14B | Շուտով | Շուտով |
| Cosmos-1.0-Autoregressive-4B | Այո՛ | Այո՛ |
| Cosmos-1.0-Autoregressive-Video2World-5B | Շուտով | Շուտով |
| Cosmos-1.0-Autoregressive-12B | Այո՛ | Այո՛ |
| Cosmos-1.0-Autoregressive-Video2World-13B | Շուտով | Շուտով |
Նշում
NeMo-ն նաև աջակցում է նախնական մարզմանը ինչպես դիֆուզիոն, այնպես էլ ավտոռեգրեսիվ ճարտարապետությունների համար։ text2world հիմքի մոդելներ։
Խոսքի արհեստական բանականություն
Խոսակցական արհեստական բանականության մոդելների մշակումը բարդ գործընթաց է, որը ներառում է մոդելների սահմանում, կառուցում և մարզում որոշակի տիրույթներում: Այս գործընթացը սովորաբար պահանջում է մի քանի իտերացիաներ՝ բարձր ճշգրտության հասնելու համար: Այն հաճախ ներառում է բազմաթիվ իտերացիաներ՝ բարձր ճշգրտության հասնելու համար, տարբեր առաջադրանքների և տիրույթին հատուկ տվյալների ճշգրտում, մարզման արդյունավետության ապահովում և մոդելների պատրաստում եզրակացության տեղակայման համար:
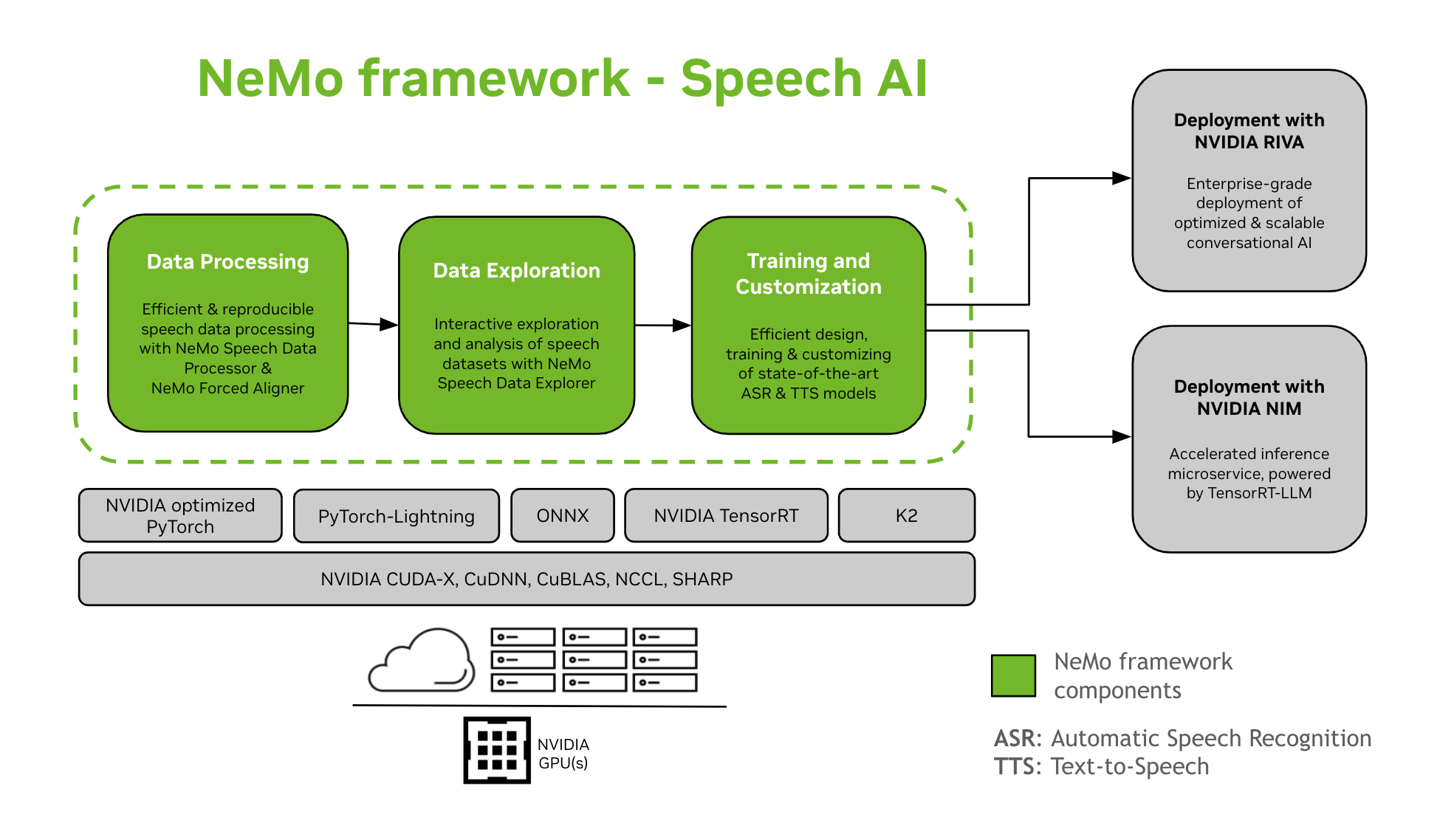
NeMo Framework-ը ապահովում է խոսքի արհեստական բանականության մոդելների ուսուցման և հարմարեցման աջակցություն: Սա ներառում է այնպիսի առաջադրանքներ, ինչպիսիք են խոսքի ավտոմատ ճանաչումը (ASR) և տեքստից խոսք (TTS) սինթեզը: Այն առաջարկում է սահուն անցում դեպի ձեռնարկությունների մակարդակի արտադրական տեղակայում NVIDIA Riva-ի միջոցով: Մշակողներին և հետազոտողներին օգնելու համար NeMo Framework-ը ներառում է ժամանակակից նախապես մարզված ստուգիչ կետեր, վերարտադրելի խոսքի տվյալների մշակման գործիքներ և խոսքի տվյալների հավաքածուների ինտերակտիվ ուսումնասիրության և վերլուծության հնարավորություններ: NeMo Framework-ի բաղադրիչները խոսքի արհեստական բանականության համար հետևյալն են.
Ուսուցում և անհատականացում
NeMo Framework-ը պարունակում է խոսքի մոդելները մարզելու և հարմարեցնելու համար անհրաժեշտ ամեն ինչ (ASR, Խոսքի դասակարգում, Խոսնակի ճանաչում, Խոսնակի դիագրամացում, և TTS) վերարտադրելի ձևով։
SOTA-ի նախապես պատրաստված մոդելներ
- NeMo Framework-ը տրամադրում է մի քանիսի ամենաժամանակակից բաղադրատոմսեր և նախապես պատրաստված ստուգիչ կետեր։ ASR և TTS մոդելներ, ինչպես նաև դրանք բեռնելու հրահանգներ։
- Խոսքի գործիքներ
- NeMo Framework-ը տրամադրում է ASR և TTS մոդելներ մշակելու համար օգտակար գործիքների մի շարք, ներառյալ՝
- NeMo հարկադիր ուղղորդիչ (NFA) տոկենների, բառերի և հատվածների մակարդակի ժամանակաչափ ստեղծելու համարampԽոսքի քանակ աուդիոյում՝ օգտագործելով NeMo-ի CTC-ի վրա հիմնված ավտոմատ խոսքի ճանաչման մոդելները։
- Խոսքի տվյալների մշակիչ (SDP), խոսքի տվյալների մշակումը պարզեցնելու գործիքակազմ։ Այն թույլ է տալիս ներկայացնել տվյալների մշակման գործողությունները կոնֆիգուրացիայում։ file, նվազագույնի հասցնելով ստանդարտ կոդը և թույլ տալով վերարտադրելիություն և համատեղ օգտագործում։
- Խոսքի տվյալների հետազոտիչ (SDE), Dash-ի վրա հիմնված web խոսքի տվյալների բազմությունների ինտերակտիվ ուսումնասիրության և վերլուծության ծրագիր։
- Տվյալների հավաքածուի ստեղծման գործիք որը տրամադրում է երկար աուդիոն հավասարեցնելու ֆունկցիոնալություն files-ը համապատասխան տառադարձումների հետ և բաժանել դրանք ավելի կարճ հատվածների, որոնք հարմար են ավտոմատ խոսքի ճանաչման (ASR) մոդելի մարզման համար։
- Համեմատության գործիք ASR մոդելների համար՝ տարբեր ASR մոդելների կանխատեսումները համեմատելու համար բառի ճշգրտության և արտասանության մակարդակի առումով։
- ASR գնահատող ASR մոդելների և այլ գործառույթների, ինչպիսիք են ձայնային ակտիվության հայտնաբերումը, կատարողականը գնահատելու համար։
- Տեքստի նորմալացման գործիք տեքստը գրավոր ձևից բանավոր ձևի փոխակերպելու և հակառակը (օրինակ՝ «31-րդ» ընդդեմ «երեսունմեկերորդի»):
- Տեղակայման ուղի
- NeMo Framework-ի միջոցով մարզված կամ հարմարեցված NeMo մոդելները կարող են օպտիմալացվել և տեղակայվել NVIDIA Riva-ի միջոցով: Riva-ն տրամադրում է կոնտեյներներ և Helm դիագրամներ, որոնք հատուկ մշակված են կոճակներով տեղակայման քայլերը ավտոմատացնելու համար:
Այլ ռեսուրսներ
- ՆեՄոNeMo Framework-ի հիմնական պահոցը
- ՆեՄո–ՎազիրԳործիք՝ մեքենայական ուսուցման փորձերը կարգավորելու, գործարկելու և կառավարելու համար։
- NeMo-Aligner: Մասշտաբային գործիքակազմ՝ մոդելի արդյունավետ համաձայնեցման համար
- NeMo-Կուրատոր՝ Իրավագիտության բակալավրիատի համար նախատեսված տվյալների նախնական մշակման և կուրացման մասշտաբային գործիքակազմ
Միացեք NeMo համայնքին, տվեք հարցեր, ստացեք աջակցություն կամ հաղորդեք սխալների մասին։
- NeMo քննարկումներ
- NeMo-ի խնդիրներ
Ծրագրավորման լեզուներ և շրջանակներ
- ՊիթոնNeMo Framework-ի օգտագործման հիմնական ինտերֆեյսը
- ՊիտորչNeMo Framework-ը կառուցված է PyTorch-ի վրա։
Լիցենզիաներ
- NeMo Github պահոցը լիցենզավորված է Apache 2.0 լիցենզիայով
- NeMo Framework-ը լիցենզավորված է NVIDIA AI ԱՊՐԱՆՔԱՅԻՆ ՀԱՄԱՁԱՅՆԱԳՐԻ համաձայն։ Կոնտեյները քաշելով և օգտագործելով՝ դուք ընդունում եք այս լիցենզիայի պայմաններն ու դրույթները։
- NeMo Framework կոնտեյները պարունակում է Llama նյութեր, որոնք կարգավորվում են Meta Llama3 համայնքի լիցենզիոն համաձայնագրով։
Ծանոթագրություններ
Ներկայումս NeMo Curator-ի և NeMo Aligner-ի աջակցությունը բազմամոդալ մոդելների համար դեռևս մշակման փուլում է և շատ շուտով հասանելի կլինի։
ՀՏՀ
Հարց. Ինչպե՞ս կարող եմ ստուգել, թե արդյոք իմ համակարգը տուժել է խոցելիությունից։
Ա. Դուք կարող եք ստուգել, թե արդյոք ձեր համակարգը տուժել է՝ ստուգելով տեղադրված NVIDIA NeMo Framework-ի տարբերակը: Եթե այն 24-րդ տարբերակից ցածր է, ձեր համակարգը կարող է խոցելի լինել:
Հարց. Ո՞վ է հաղորդել CVE-2025-23360 անվտանգության խնդրի մասին։
Ա. Անվտանգության խնդրի մասին հաղորդել է Օր Պելեսը՝ JFrog Security-ն: NVIDIA-ն շնորհակալություն է հայտնում նրանց ներդրման համար:
Հարց. Ինչպե՞ս կարող եմ ստանալ ապագա անվտանգության ծանուցումների ծանուցումներ:
Ա. Այցելեք NVIDIA արտադրանքի անվտանգության էջը՝ անվտանգության ծանուցումներին բաժանորդագրվելու և արտադրանքի անվտանգության թարմացումների մասին տեղեկացված մնալու համար:
Փաստաթղթեր / ռեսուրսներ
 | NeMo Framework |
Հղումներ
- Օգտագործողի ձեռնարկmanual.tools